Introducción a R: Comandos para Test
2023
library(tidyverse)
library(car)
library(ggplot2)
library(ggwithimages)
library(multcompView)
library(gridExtra)
library(grid)
library(fishdata)Datos a cargar para trabajar
data(adult_metrics)
datos<- adult_metricsGeneramos algunos factores a partir de variables del set de datos para poder aplicar test estadísticos básicos
datos15 <-datos %>%
mutate(edad_g = if_else(age > 300,
"viejo",
"joven"))
datos16 <-datos15 %>%
mutate(type_g = ifelse(datos$growth_rate > 2, "High",
ifelse(datos$growth_rate > 1.9, "Medium","Low")))
Test de hipótesis
Un factor (dos niveles) Test de t
H0: µ_viejo=µ_joven
Ha: µ_viejo≠µ_joven
t.test(y~x,data=datos, paired=FALSE, var.equal =TRUE)
t.test(y~x,data=datos, paired=FALSE, var.equal =FALSE)
Notese que var.equal= FALSE se utiliza si no tenemos
homogeneidad de varianza
Supuestos en general
Normalidad
Homocedasticidad (dos opciones)
Independecia
Evaluación de los supuestos en análisis de dos muetras (test t)
Prueba de normalidad Shapiro-Wilk
Hipótesis
H0: Las variables siguen distribución normal
Ha: Las variables no siguen distribución normal
Prueba de normalidad Shapiro-wilk para las variables respuesta
#tt$Longitud_total<-as.numeric(tt$Longitud_total)
# Hacemos una función para el test de Sahpiro
shp_test <- function(datos16){
st <- shapiro.test(datos16$growth_rate)
data.frame(st$method, st$statistic, st$p.value)
}
datos16%>%
group_by(edad_g) %>%
do(shp_test(.)) %>%
ungroup()Gráficamente
p <- datos16 %>%
ggplot( aes(x=growth_rate, fill=edad_g)) +
geom_histogram( color="#e9ecef", alpha=0.6, position = 'identity') +
scale_fill_manual(values=c("#69b3a2", "#404080")) +
geom_line(stat = "density")+
facet_grid(~edad_g)
labs(fill="")
#> $fill
#> [1] ""
#>
#> attr(,"class")
#> [1] "labels"
p
#> `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.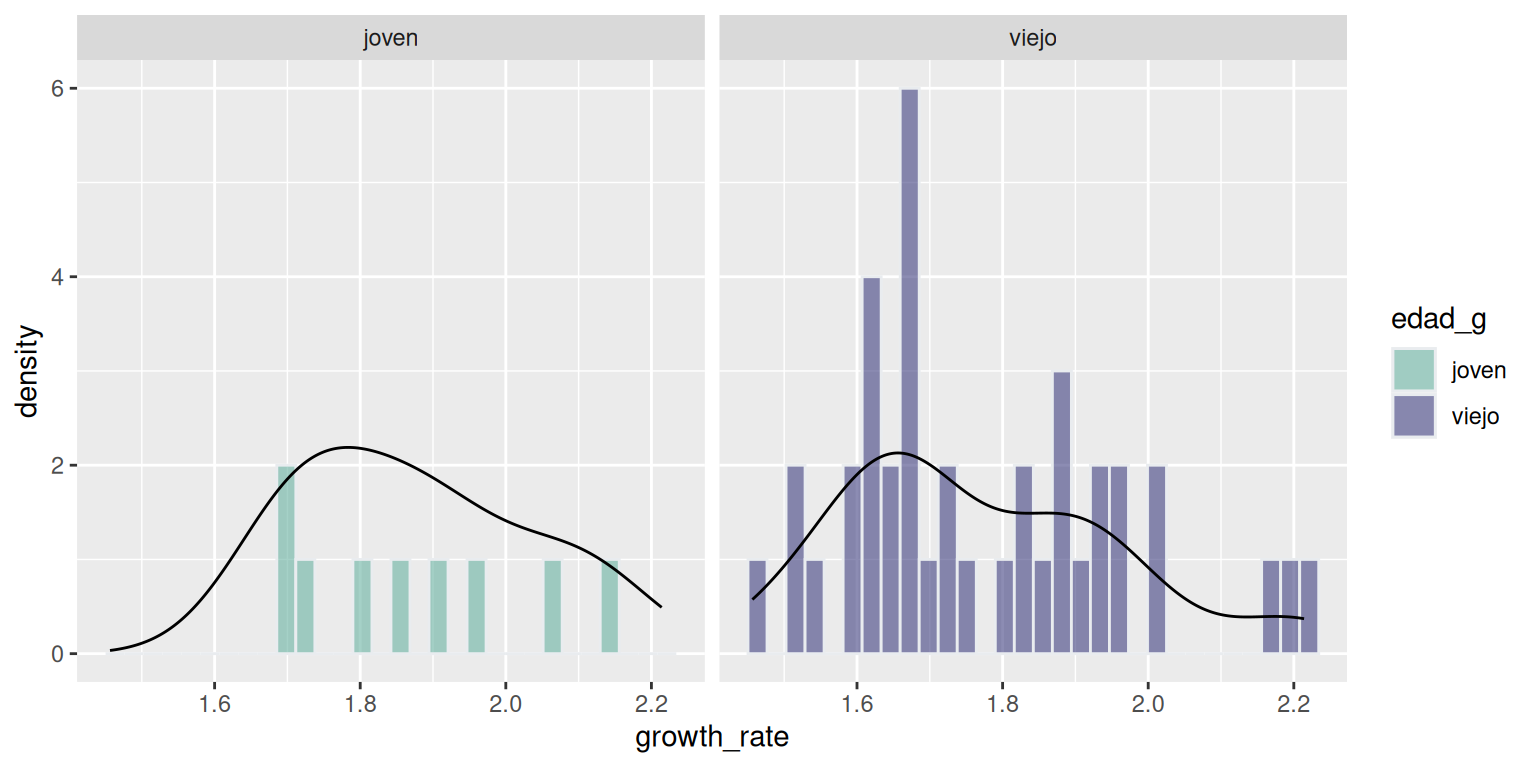
Trasformamos la variable para poder aceptar el supuesto de normalidad
p1 <- datos %>%
ggplot( aes(x=log_growth_rate, fill=edad_g)) +
geom_histogram( color="#e9ecef", alpha=0.6, position = 'identity') +
scale_fill_manual(values=c("#69b3a2", "#404080")) +
geom_line(stat = "density")+
facet_grid(~edad_g)
labs(fill="")
#> $fill
#> [1] ""
#>
#> attr(,"class")
#> [1] "labels"
p1
#> `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.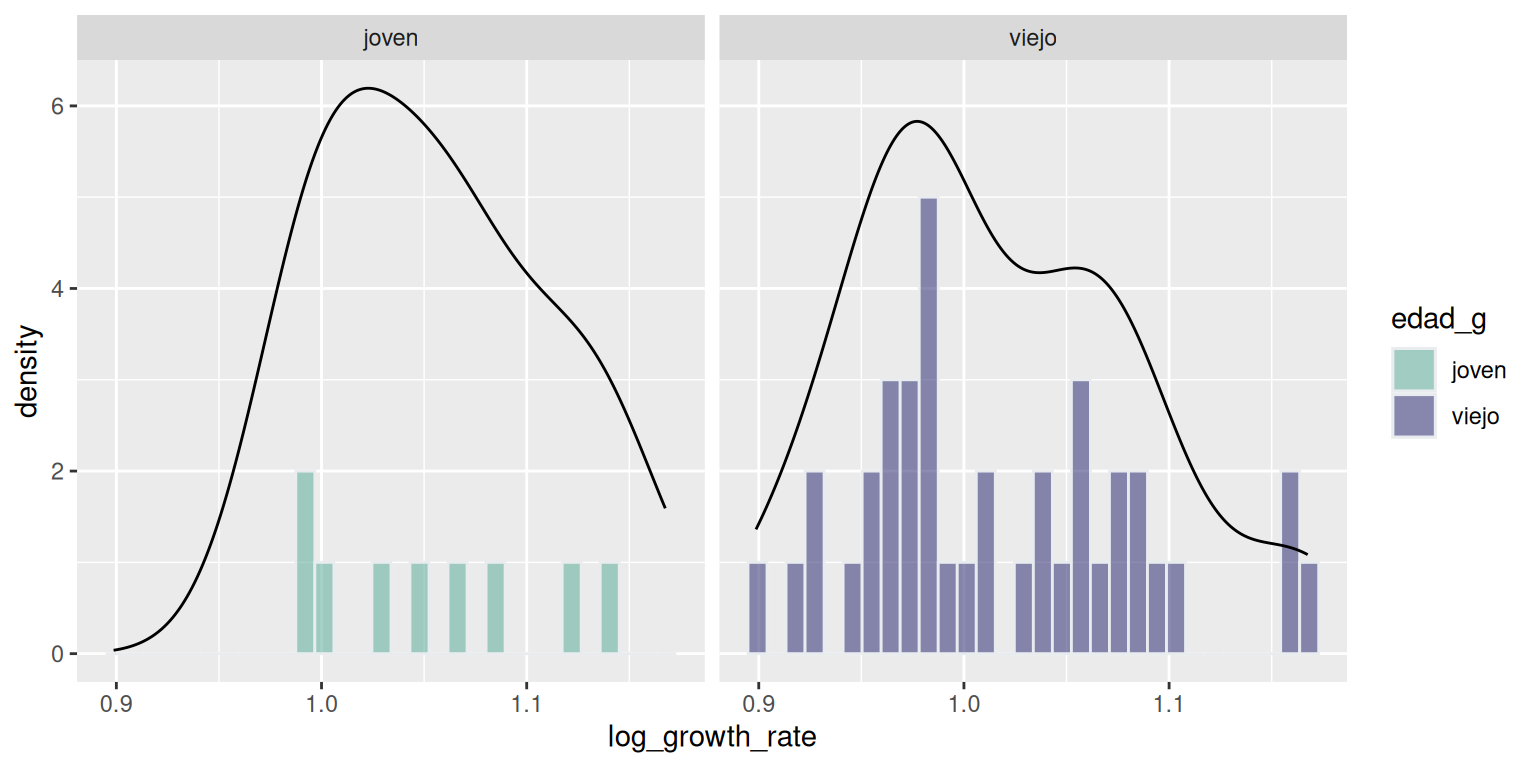
Igualdad de varianzas es análisis de dos muetras
Hipótesis
H0: Las variables siguen distribución normal
Ha: Las variables no siguen distribución normal
Prueba de homocedasticidad Prueba de Bartlett o Levene para las variables respuesta
Prueba
datos<-datos16%>%
mutate(log_growth_rate = log1p(growth_rate))
bartlett.test(log_growth_rate ~ edad_g, data = datos)
#>
#> Bartlett test of homogeneity of variances
#>
#> data: log_growth_rate by edad_g
#> Bartlett's K-squared = 0.5239, df = 1, p-value = 0.4692
leveneTest(growth_rate ~ edad_g, data = datos)
#> Warning in leveneTest.default(y = y, group = group, ...): group
#> coerced to factor.
Prueba de Levene
t.test(y~x,data=datos, paired=FALSE, var.equal =TRUE)
t.test(y~x,data=datos, paired=FALSE, var.equal =FALSE)
Nótese que var.equal= FALSE se utiliza si no tenemos
homogeneidad de varianza
datos<-datos16%>%
mutate(log_growth_rate = log1p(growth_rate))
t.test(log_growth_rate~edad_g,data=datos, paired=FALSE, var.equal =TRUE)
#>
#> Two Sample t-test
#>
#> data: log_growth_rate by edad_g
#> t = 1.5067, df = 46, p-value = 0.1387
#> alternative hypothesis: true difference in means between group joven and group viejo is not equal to 0
#> 95 percent confidence interval:
#> -0.01225356 0.08519184
#> sample estimates:
#> mean in group joven mean in group viejo
#> 1.053967 1.017498
box_plot <- ggplot(datos, aes(x =edad_g, y=log_growth_rate))
# Add the geometric object box plot
box_plot +
geom_boxplot()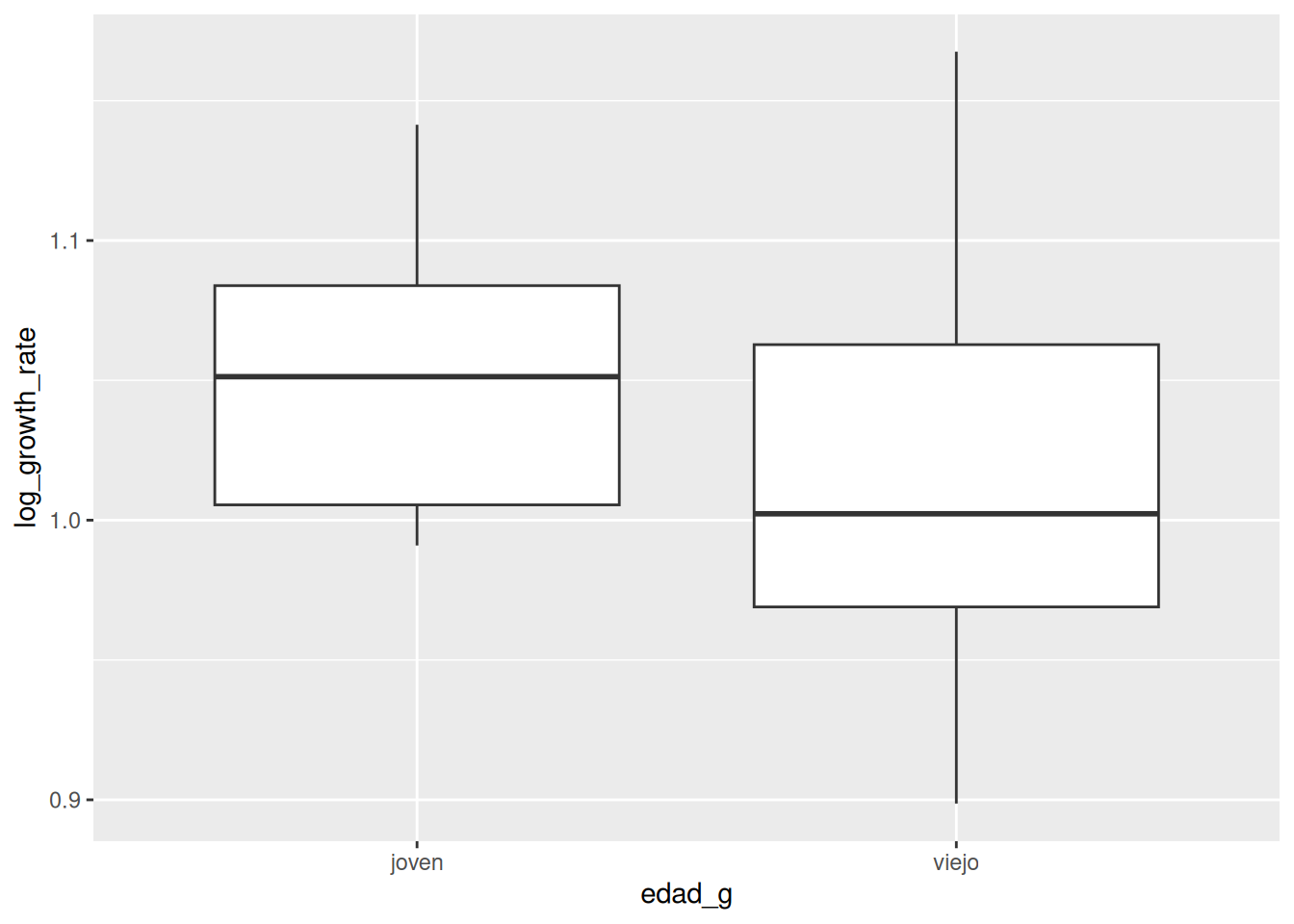
Evaluación de los Supuestos del modelo ANOVA
Prueba de normalidad Shapiro-Wilk
H0: Los residuos siguen la distribución normal
Ha: Los residuos no siguen la distribución normal
Prueba de normalidad Shapiro-wilk para los residuos
m1<-aov(growth_rate~type_g,data=datos16)
m2 <- lm(growth_rate~type_g,data=datos16)
print(m1)
#> Call:
#> aov(formula = growth_rate ~ type_g, data = datos16)
#>
#> Terms:
#> type_g Residuals
#> Sum of Squares 1.153647 0.498088
#> Deg. of Freedom 2 45
#>
#> Residual standard error: 0.1052075
#> Estimated effects may be unbalanced
print(m2)
#>
#> Call:
#> lm(formula = growth_rate ~ type_g, data = datos16)
#>
#> Coefficients:
#> (Intercept) type_gLow type_gMedium
#> 2.1339 -0.4323 -0.1878
summary(m1)
#> Df Sum Sq Mean Sq F value Pr(>F)
#> type_g 2 1.1536 0.5768 52.11 1.93e-12 ***
#> Residuals 45 0.4981 0.0111
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
summary(m2)
#>
#> Call:
#> lm(formula = growth_rate ~ type_g, data = datos16)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -0.245303 -0.060828 -0.005251 0.054704 0.195197
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 2.13390 0.04295 49.682 < 2e-16 ***
#> type_gLow -0.43230 0.04649 -9.299 4.81e-12 ***
#> type_gMedium -0.18777 0.05853 -3.208 0.00246 **
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 0.1052 on 45 degrees of freedom
#> Multiple R-squared: 0.6984, Adjusted R-squared: 0.685
#> F-statistic: 52.11 on 2 and 45 DF, p-value: 1.931e-12
anova(m1)anova(m2)
res1=residuals(m2,type="response")
stm <- shapiro.test(res1)
print(stm)
#>
#> Shapiro-Wilk normality test
#>
#> data: res1
#> W = 0.97894, p-value = 0.5351
bartlett.test(growth_rate~type_g, data = datos16)
#>
#> Bartlett test of homogeneity of variances
#>
#> data: growth_rate by type_g
#> Bartlett's K-squared = 10.274, df = 2, p-value = 0.005877
leveneTest(growth_rate~type_g, data = datos16)
#> Warning in leveneTest.default(y = y, group = group, ...): group
#> coerced to factor.
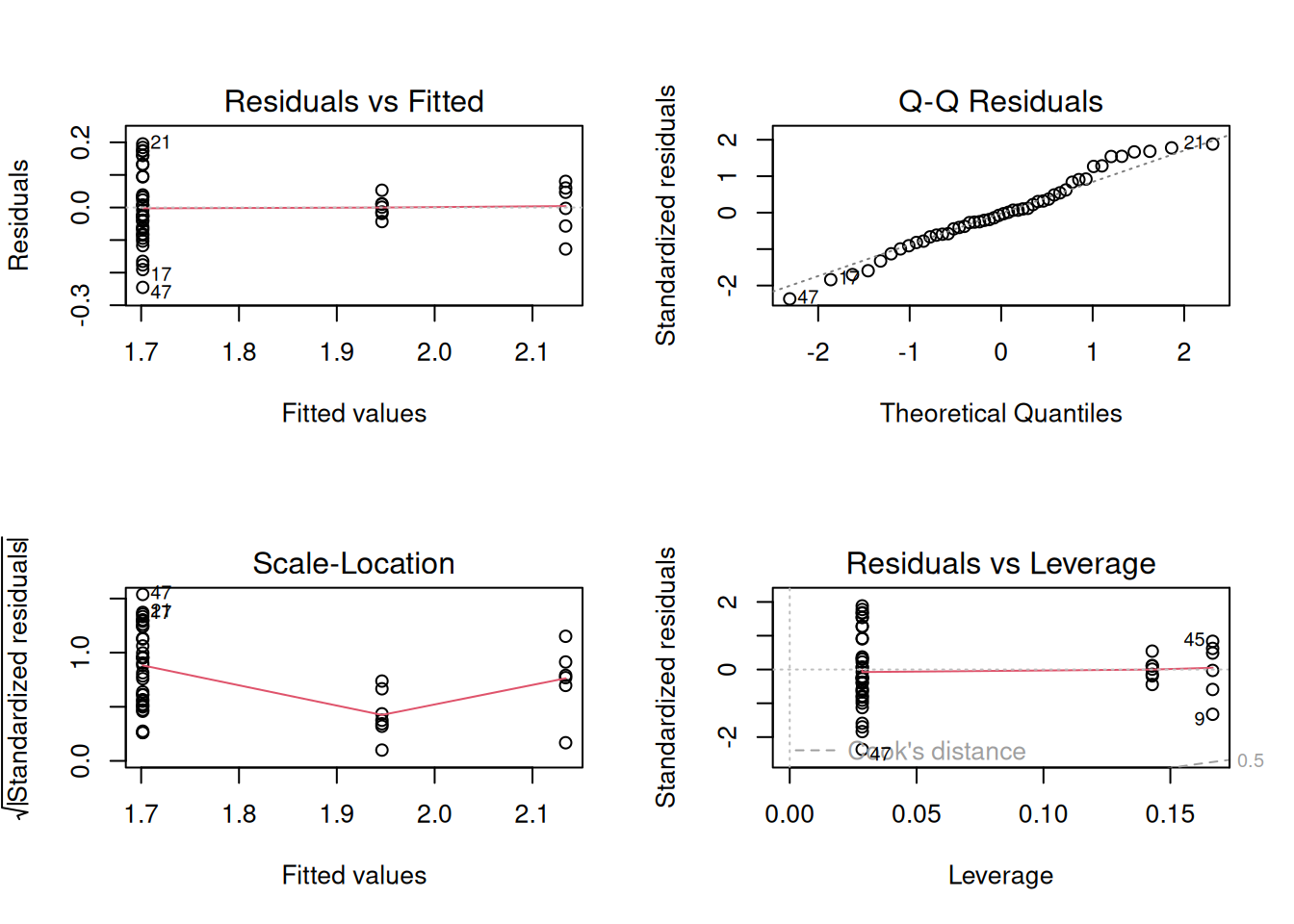
Transformando
datos1<-datos16%>%
mutate(sqrt_growth_rate = sqrt(growth_rate))
m3 <- aov(sqrt_growth_rate~type_g, data=datos1)
print(m3)
#> Call:
#> aov(formula = sqrt_growth_rate ~ type_g, data = datos1)
#>
#> Terms:
#> type_g Residuals
#> Sum of Squares 0.15394964 0.07231319
#> Deg. of Freedom 2 45
#>
#> Residual standard error: 0.0400869
#> Estimated effects may be unbalanced
summary(m3)
#> Df Sum Sq Mean Sq F value Pr(>F)
#> type_g 2 0.15395 0.07697 47.9 7.14e-12 ***
#> Residuals 45 0.07231 0.00161
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
anova(m3)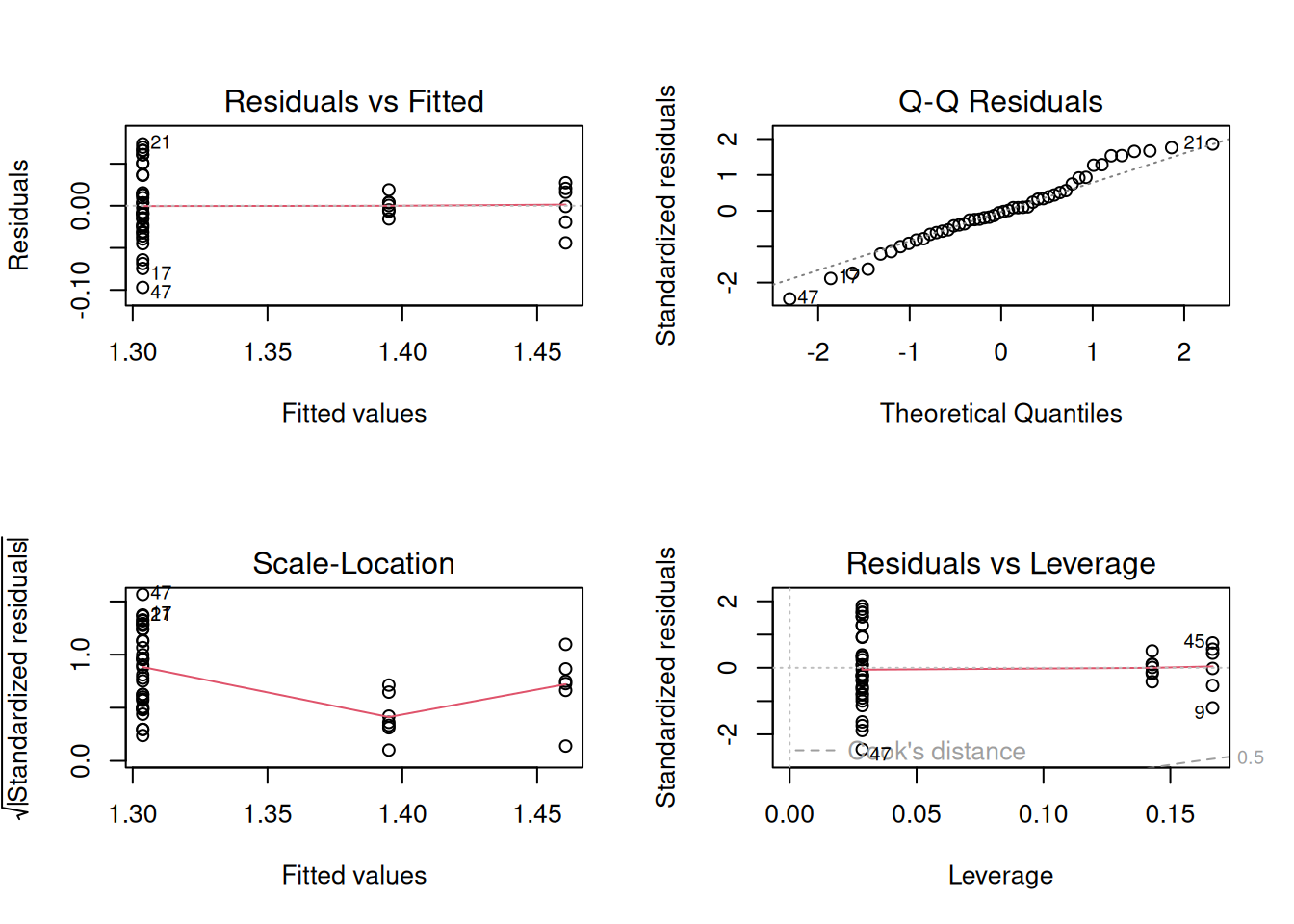
res2=residuals(m3,type="response")
stm <- shapiro.test(res2)
print(stm)
#>
#> Shapiro-Wilk normality test
#>
#> data: res2
#> W = 0.97687, p-value = 0.4558
bartlett.test(sqrt_growth_rate~type_g, data = datos1)
#>
#> Bartlett test of homogeneity of variances
#>
#> data: sqrt_growth_rate by type_g
#> Bartlett's K-squared = 11.492, df = 2, p-value = 0.003195
Posthoc numerico
t <-TukeyHSD(m3)
t <-TukeyHSD(m3)
print(t)
#> Tukey multiple comparisons of means
#> 95% family-wise confidence level
#>
#> Fit: aov(formula = sqrt_growth_rate ~ type_g, data = datos1)
#>
#> $type_g
#> diff lwr upr p adj
#> Low-High -0.15686210 -0.19979084 -0.11393336 0.0000000
#> Medium-High -0.06557215 -0.11962430 -0.01152001 0.0140265
#> Medium-Low 0.09128995 0.05106389 0.13151600 0.0000051
Posthoc gráfico
boxplot(sqrt_growth_rate ~ type_g,data=datos1, ylim=c(1.2,1.5),
xlab="Type", ylab="Sqrt(growth_rate)", col=(c("gold","darkgreen", "white")))
tp <- extract_p(t)
groups2 <- multcompLetters(t$type_g[,3])
lets <- groups2$Letters[c(2,1:2)]
text(1:2, 1.5 ,lets)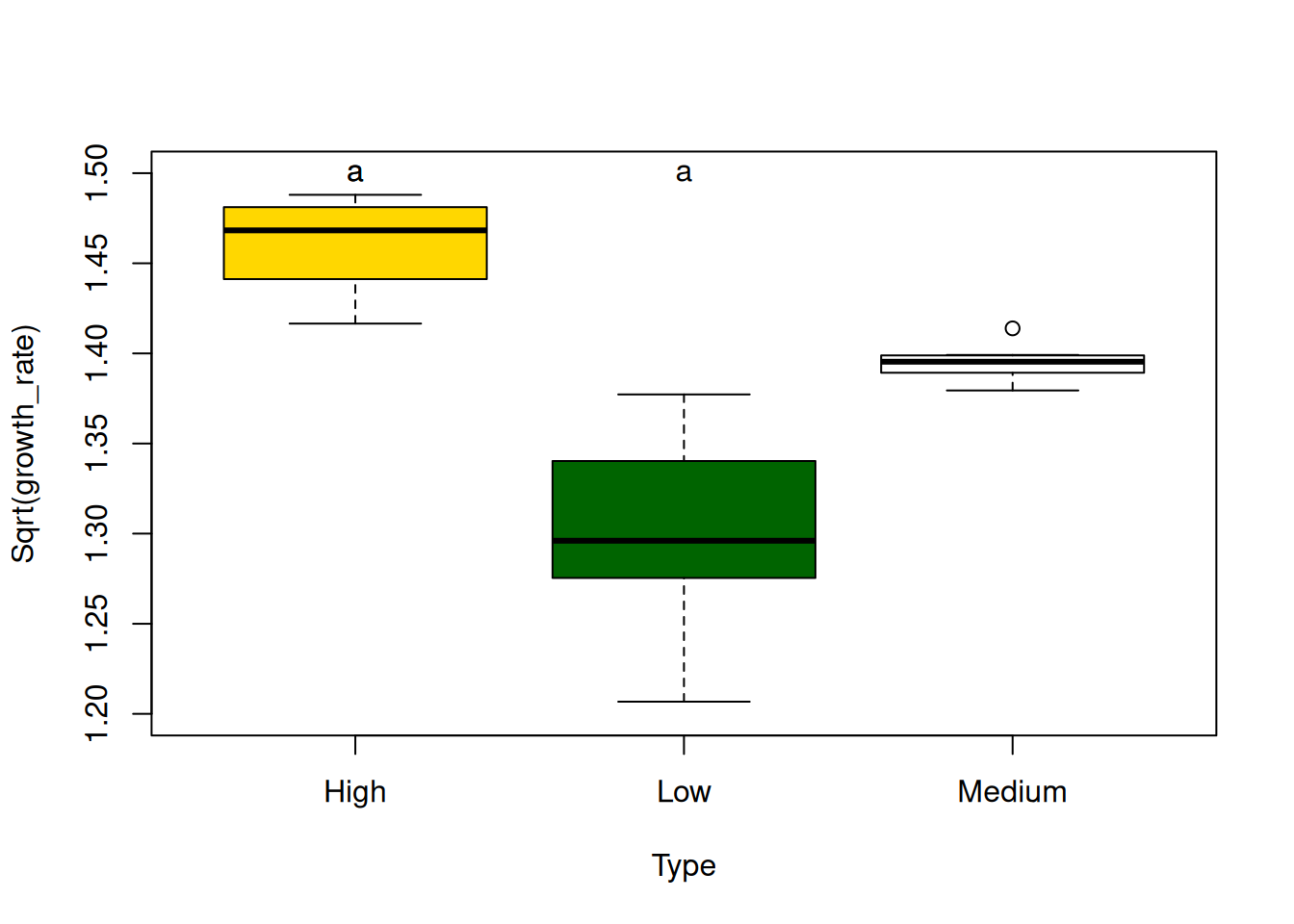
###Ejercicios fase III
Ahora vamos a explorar los efectos de los mariscos en la felicidad humana.
Pero…

Los datos de tu última investigación se han mezclado con datos de una
competencia de comer almejas crudas con limón y gin que hicieron durante
la campaña. Ahora con la ayuda de tidyverse en combinación con pruebas
de hipótesis y diagnóstico de supuestos vas a volver a obtener
resultados confiables.
# Generar la estructura del data frame 'mariscos'
mariscos <- data.frame(
Nombres = c("Almeja", "Ostra", "Langosta", "Cangrejo", "Pulpo"),
Nivel_Picante = c(9, 4, 8, 6, 7),
Tiempo_Coccion = c("3:30", "2:45", "5:15", "4:00", "6:20"),
Puntaje_Felicidad = c(8.2, 7.5, 9.0, 6.8, 8.5),
Consumo_Picante = c("Sí", "No", "Sí", "No", "Sí")
)
# Mostrar los datos generados
mariscos-Nombres: El nombre del marisco.
-Nivel_Picante: El nivel de picante del marisco en una escala del 1 al 10.
-Tiempo_Cocción: El tiempo de cocción del marisco en formato “minutos:segundos”.
-Puntaje_Felicidad: El puntaje de felicidad asignado al marisco en una escala del 1 al 10.
-Consumo_Picante: Indica si el marisco se consume picante o no.
Vamos a utilizar los comandos del paquete tidyverse para limpiar y
analizar los datos de mariscos en un archivo desordenado llamado
‘MariscosLocos.csv’. Además, deberás realizar pruebas de hipótesis y
diagnosticar supuestos para obtener conclusiones científicas sustentadas
estadísticamente.
a- Utilizando dplyr, filtra solo los registros de
mariscos con un nivel de picante superior a 7 y crea una nueva columna
llamada ‘Intensidad_Picante’ para clasificarlos como ‘Peligroso’ o
‘Extremo’, según su nivel de picante.
mariscos_filtrados <- mariscos %>%
filter(Nivel_Picante > 7) %>%
mutate(Intensidad_Picante = ifelse(Nivel_Picante > 10, "Extremo", "Peligroso"))
mariscos_filtrados
b- Utiliza tidyr para separar la columna
‘Tiempo_Coccion’ en ‘Minutos’ y ‘Segundos’, y luego conviértelos a una
unidad de tiempo única (segundos, por ejemplo).
mariscos_limpio <- mariscos %>%
separate(Tiempo_Coccion, into = c("Minutos", "Segundos"), sep = ":") %>%
mutate(Tiempo_Total = as.numeric(Minutos) * 60 + as.numeric(Segundos))
mariscos_limpio
c- Realiza un análisis de supuestos para diagnosticar la
normalidad de la variable ‘Puntaje_Felicidad’ entre los participantes.
Crea un gráfico de densidad y un gráfico cuantil-cuantil (QQ plot) para
visualizar la distribución.
qqnorm(mariscos$Puntaje_Felicidad)
qqline(mariscos$Puntaje_Felicidad)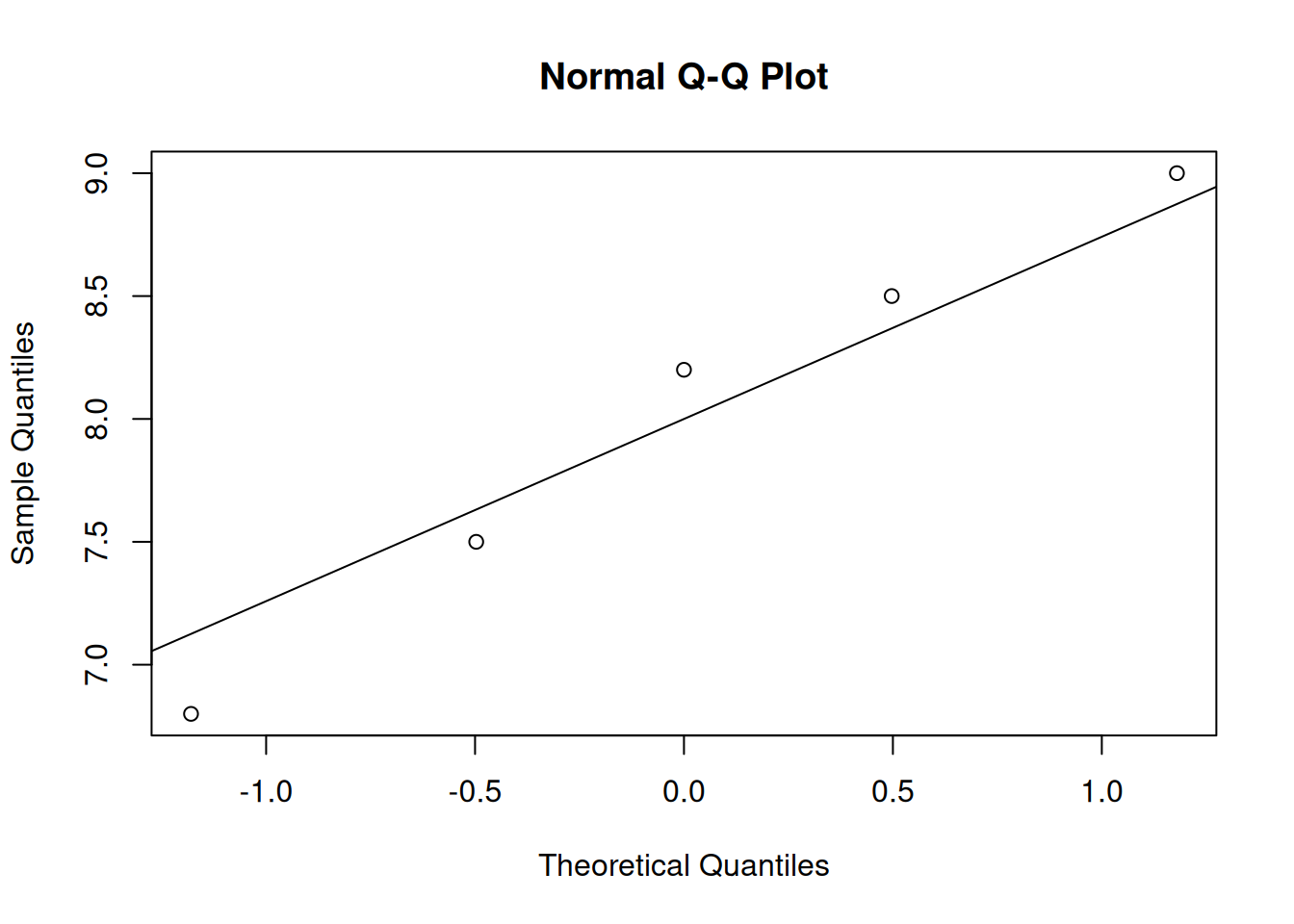
leveneTest(Puntaje_Felicidad ~ Consumo_Picante, data = mariscos)
#> Warning in leveneTest.default(y = y, group = group, ...): group
#> coerced to factor.
d- Realiza una prueba de hipótesis para determinar si
existe una diferencia significativa en el puntaje de felicidad entre los
participantes que consumieron mariscos picantes y los que no. Utiliza la
función t.test para comparar las dos muestras y presenta los resultados
de manera clara.
t.test(Puntaje_Felicidad ~ Consumo_Picante, data = mariscos)
#>
#> Welch Two Sample t-test
#>
#> data: Puntaje_Felicidad by Consumo_Picante
#> t = -3.3678, df = 1.8989, p-value = 0.08373
#> alternative hypothesis: true difference in means between group No and group Sí is not equal to 0
#> 95 percent confidence interval:
#> -3.3221441 0.4888107
#> sample estimates:
#> mean in group No mean in group Sí
#> 7.150000 8.566667