Introducción al lenguaje de programación R y su aplicación en análisis estadísticos (2023)
Datos ordenado (tydiverse)
Objetivos del día
Seguir aprendiendo a trabajar con una planilla de datos sin modificarla de raíz (Tidy data).
Seguir explorando la lógica básica de algunas funciones fundamentales de R (para manipular y administrar datos) y crear código legibles.
“Las familias felices son todas iguales, cada familia infeliz lo es a su manera”
— León Tolstoi
“Los conjuntos de datos ordenados son todos iguales, pero cada conjunto de datos desordenado es desordenado a su manera”
— Hadley Wickham
Libros de Hadley: Wickham
Poner datos en formato tidy requiere un poco de trabajo previo… pero, una vez que tenga los datos ordenados

pasaran mucho menos tiempo acomodando datos de una estructura a otra, lo que les permitirá dedicar más tiempo a las cuestiones analíticas que tenga entre manos.
Los paquetes que forman parte del tidyverso son:
readr (Importar datos y otras cosas)
dplyr (Arreglar)
tidyr (Ordenar)
magittr (%>%, programar)
ggplot2 (Gráficar)
purrr (Loops)
forcats (Para variables categóricas)
stringr (Para carácteres, palabras)
Tidyverse
Tidyverse es una colección de paquetes de R diseñados para la ciencia de datos. Todos los paquetes comparten una filosofía subyacente y APIs (Application Programming Interfaces) comunes (piezas de código que permite a diferentes aplicaciones comunicarse entre sí y compartir información y funcionalidades) http://tidyverse.org.

Tidy data (datos limpios)

Ordenar la información de un conjunto de datos y se rige por tres críterios:
Cada observación está en una fila.
Cada variable está en una columna.
Cada valor tiene su propia celda.

Paquetes
# install.packages("tidyverse")
library(tidyverse)
readr(read_csv())
magrittr (%>%)dplyr(filter, select, arrange, mutate, summarise, etc.)tidyr(pivot, join, gether, merge, etc.)ggplot2(geom_point, geom_bar, geom_col, etc. )
Podemos importar datos por diferentes vias y hasta cambia según sistema operativo.
setwd("") : Fija el directorio de trabajo.
getwd("") : Mirar en que directorio estoy
trabajando.
setwd ("/run/media/kechu/Kechu/R_imagenes/")
![]()
read _csv() y read _csv2() : para archivos
csv.
read _tsv() : separados por tabulaciones.
read _fwf() : ni idea.
read _log() : archivos web.
Vamos a utilizar datos del paquetes FishData:
adult_metrics

datos<- adult_metricshead() : Muestra las primas 5 filas de los datos (es
útil para recordar nombres de variables).
head(datos)
str() : Nos índica que estructura tienen los datos (que
variables es continúa, discreta, factor, etc.).
str(datos)
#> 'data.frame': 48 obs. of 6 variables:
#> $ fish_code : chr "H.1" "H.2" "H.3" "H.4" ...
#> $ standard_length: num 5.63 5.84 5.88 5.33 6.87 ...
#> $ body_depth : num 0.817 0.768 0.824 0.543 0.827 ...
#> $ age : int 274 317 298 305 291 296 288 370 309 358 ...
#> $ birthdate : Date, format: "2015-06-25" "2015-05-26" ...
#> $ growth_rate : num 1.69 1.93 1.8 1.83 2.08 ...glimpse() : Es como una versión transpuesta de
print().
glimpse(datos)
#> Rows: 48
#> Columns: 6
#> $ fish_code <chr> "H.1", "H.2", "H.3", "H.4", "H.7", "H.9", "H.10", "H.…
#> $ standard_length <dbl> 5.631, 5.838, 5.876, 5.330, 6.873, 4.752, 5.183, 6.59…
#> $ body_depth <dbl> 0.817, 0.768, 0.824, 0.543, 0.827, 0.559, 0.572, 0.62…
#> $ age <int> 274, 317, 298, 305, 291, 296, 288, 370, 309, 358, 346…
#> $ birthdate <date> 2015-06-25, 2015-05-26, 2015-06-14, 2015-06-07, 2015…
#> $ growth_rate <dbl> 1.6938, 1.9324, 1.7972, 1.8331, 2.0771, 1.7332, 2.131…
Ahora le agregamos unas filas como factor para poder aplicar ejercicios… (edad_g, type_g)
datos15 <-datos %>%
mutate(edad_g = ifelse(age > 300, "viejo", "joven"))
datos16 <-datos15 %>%
mutate(type_g = ifelse(datos$growth_rate > 2, "High",
ifelse(datos$growth_rate > 1.9, "Medium","Low")))
glimpse(datos15)
#> Rows: 48
#> Columns: 7
#> $ fish_code <chr> "H.1", "H.2", "H.3", "H.4", "H.7", "H.9", "H.10", "H.…
#> $ standard_length <dbl> 5.631, 5.838, 5.876, 5.330, 6.873, 4.752, 5.183, 6.59…
#> $ body_depth <dbl> 0.817, 0.768, 0.824, 0.543, 0.827, 0.559, 0.572, 0.62…
#> $ age <int> 274, 317, 298, 305, 291, 296, 288, 370, 309, 358, 346…
#> $ birthdate <date> 2015-06-25, 2015-05-26, 2015-06-14, 2015-06-07, 2015…
#> $ growth_rate <dbl> 1.6938, 1.9324, 1.7972, 1.8331, 2.0771, 1.7332, 2.131…
#> $ edad_g <chr> "joven", "viejo", "joven", "viejo", "joven", "joven",…
glimpse(datos16)
#> Rows: 48
#> Columns: 8
#> $ fish_code <chr> "H.1", "H.2", "H.3", "H.4", "H.7", "H.9", "H.10", "H.…
#> $ standard_length <dbl> 5.631, 5.838, 5.876, 5.330, 6.873, 4.752, 5.183, 6.59…
#> $ body_depth <dbl> 0.817, 0.768, 0.824, 0.543, 0.827, 0.559, 0.572, 0.62…
#> $ age <int> 274, 317, 298, 305, 291, 296, 288, 370, 309, 358, 346…
#> $ birthdate <date> 2015-06-25, 2015-05-26, 2015-06-14, 2015-06-07, 2015…
#> $ growth_rate <dbl> 1.6938, 1.9324, 1.7972, 1.8331, 2.0771, 1.7332, 2.131…
#> $ edad_g <chr> "joven", "viejo", "joven", "viejo", "joven", "joven",…
#> $ type_g <chr> "Low", "Medium", "Low", "Low", "High", "Low", "High",…
Para evitar declaraciones anidadas (%>%)

¿Por qué pipe?

# Aninado
mean(sqrt(datos$growth_rate))
#> [1] 1.336632
# Pipe lineal
datos$growth_rate%>%sqrt%>%mean
#> [1] 1.336632
# Pipe ordenado
datos$growth_rate%>%
sqrt%>%
mean
#> [1] 1.336632Vamos a correr un ejemplo
Vamos a calcular el logaritmo de la variable growth_rate
y que nos devuelva las diferencias convenientemente retardadas e
iteradas y sumando además una función exponencial y vamos a expresar el
resultado redondeado a un decímal…

round(exp(diff(log(datos$growth_rate))), 1)
#> [1] 1.1 0.9 1.0 1.1 0.8 1.2 0.8 1.2 0.8 1.0 1.1 1.1 0.9 1.3 0.7 0.9 1.2 1.0
#> [19] 0.9 1.0 0.9 1.2 0.8 1.0 1.0 1.1 0.9 1.0 1.3 0.9 0.9 1.1 1.1 0.9 0.9 1.0
#> [37] 0.9 1.2 0.9 1.1 0.8 0.9 1.1 1.3 0.9 0.7 1.2
resultado <-datos$growth_rate %>%
log() %>% # Calcula el logaritmo natural de
diff() %>% # Calcula la diferencia entre elementos consecutivos
exp() %>% # Calcula el exponencial de la diferencia
round(1) # Redondea el resultado a 1 decimal
resultado
#> [1] 1.1 0.9 1.0 1.1 0.8 1.2 0.8 1.2 0.8 1.0 1.1 1.1 0.9 1.3 0.7 0.9 1.2 1.0
#> [19] 0.9 1.0 0.9 1.2 0.8 1.0 1.0 1.1 0.9 1.0 1.3 0.9 0.9 1.1 1.1 0.9 0.9 1.0
#> [37] 0.9 1.2 0.9 1.1 0.8 0.9 1.1 1.3 0.9 0.7 1.2
Vamos a correr un ejemplo dónde se ve la eficacia de pipe bajo ciertas circunstancias (comandos complejos)
ptm <- Sys.time()
#split the data on the number of cylinders
big.l<-split(tmp.data,tmp.data$group)
#apply some function of interest to all columns
results<-lapply(big.l, function(x) apply(x,2,median))
#bind results and add splitting info
results<-data.frame(group=names(results),do.call("rbind",results))
#elapsed time
(bd<-Sys.time()-ptm )
#> Time difference of 0.3981311 secsModo anidado
==Time difference of 0.4395719 secs==

ptm <- Sys.time()
results <- tmp.data %>%
group_by(group) %>%
summarise(across(everything(), median))
#elapsed time
(ad<-Sys.time()-ptm )
#> Time difference of 0.3147013 secsModo pipe
==Time difference of 0.0.3366137 secs==

Si la ejecuto dos veces por día ahorro 0.25 segundos de mi vida! A 20 funciones por día en 365 días del año, nos ahorra 15 minutos por año.
![]()

Seleccionando variables select
da <-datos %>% select(fish_code, age, growth_rate)
da %>% head(3)
# Hacer una selección negativa
dat <- datos%>%
select(!(age))
dat %>% head(3)
# Otra opción
dat2 <- datos%>%
select(-age)
dat2 %>% head(3)
Filtrando variables filter

# Seleccionar un nivel de una variable específica
dat <- datos16 %>%
filter(fish_code == "H.1")
dat%>% head(3)
# Seleccionar un nivel de dos variables específicas
dat1 <- datos16 %>%
filter(edad_g == "joven" & type_g== "Low")
dat1 %>% head(3)
# Seleccionar un nivel de dos variables específicas
dat1 <- datos16 %>%
filter(edad_g == "joven" | type_g== "Low")
dat1 %>% head(3)
# Umbral para variable continua
dat2 <- datos16 %>%
filter (growth_rate> 2)
dat2 %>% head(3)
dat2 <- datos16 %>%
filter (growth_rate==0)
dat2 %>% head(3)
dat3 <- datos16 %>%
filter (!growth_rate==0)
dat3 %>% head(3)
Acá hay un link con muchos ejemplos: filter
Conclusión:
Legibilidad del código es superior, los pipes permiten encadenar las operaciones de manera más fluida y fácil de entender.
El uso de pipes reduce la necesidad de crear variables intermedias, lo que puede simplificar el código y hacerlo más eficiente.
El código natural de R (sin el pipe natural) puede requerir la creación de variables adicionales para almacenar los resultados intermedios de cada operación.
Ejercicios fase I y II

Supongamos que tenemos un conjunto de datos llamado “m_m” que contiene información sobre diferentes especies de mamíferos marinos. Queremos realizar las siguientes tareas utilizando tanto el comando pipe (%>%) como códigos anidados de R:
Utilizando pipes y manera base de R:
a. Selecciona las columnas “Especie”, “Longitud”, “Peso”
y “Familia”, utilizando modo anidado y pipe.
b. Filtra sólo los mamíferos de la familia “Phocidae”,
utilizando modo anidado y pipe.
c. Completa todo en un sólo código, sólo con pipe.
m_m <- data.frame(
Especie = c("Foca-freddy", "Delfín-flipper", "Ballena-migaloo", "León marino-aslan", "Orca-willy"),
Familia = c("Phocidae", "Delphinidae", "Balaenopteridae", "Otariidae", "Delphinidae"),
Longitud = c(2.5, 3.2, 18.7, 2.1, 9.5),
Peso = c(150, 200, 2500, 180, 400),
Habitat = c("Ártico", "Océano Atlántico", "Océano Pacífico", "Mar Mediterráneo", "Océano Atlántico")
)
# Mostrar los datos generados
head(m_m)-Especie: Nombre de individuos famosos.
-Familia: Relacionada a la especie.
-Longitud: Longitud del animal en “metros”.
-Peso: Peso del animal en “kg”.
-Habitat: Zona donde habita.
Cambiar el nombre y agregar y/o hacer operaciones de variables
mutate
mutate( .data, …, .by = NULL, .keep = c(“all”, “used”, “unused”, “none”), .before = NULL, .after = NULL )
.by
Opcionalmente, una selección de columnas por las que agrupar sólo para esta operación, funcionando como alternativa a group_by().
.keep Controla qué columnas de los datos se mantienen en
la salida.
“all” conserva todas las columnas de los datos y es el valor por defecto.
“used” conserva sólo las columnas utilizadas en … para crear nuevas columnas. Esto es útil para comprobar su trabajo, ya que muestra las entradas y salidas una al lado de la otra.
“unused” conserva sólo las columnas no utilizadas.
“none” Sólo se conservan las variables de agrupación y las columnas creadas.
.before, .after
Opcionalmente, se puede controlar dónde deben aparecer las nuevas
columnas (por defecto se añaden a la derecha). Véase
relocate() para más detalles.
Funciones útiles de mutate
+, -, log(), etc.
lead(), lag()
dense_rank(), min_rank(), percent_rank(), row_number(), cume_dist(), ntile()
cumsum(), cummean(), cummin(), cummax(), cumany(), cumall()
na_if(), coalesce()
if_else(), recode(), case_when()
# Agregar una variable nueva
tt<-datos %>%
mutate(edad_g = if_else(age > 300,
"viejo",
"joven"))
tt%>%
head()
# Agregar variables separadas según condicionales
datos1 <- datos %>%
mutate(type_g = ifelse(datos$growth_rate > 2, "High",
ifelse(datos$growth_rate > 1.9, "Medium","Low")))
datos1%>% head(10)
# Agregar variables separadas según condicionales
datos1 <- datos %>%
mutate(type_g = case_when(
growth_rate > 2 ~ "High",
growth_rate > 1.9 ~ "Medium",
growth_rate < 1.9 ~ "Low"))
datos1%>%
head(10)
# Agregar variables aplicando funciones
datos2 <-datos1 %>%
select(growth_rate,type_g) %>%
mutate(growth_rate2 = growth_rate * 2,
growth_rate2_squared = growth_rate2 * growth_rate2)
datos2%>%
head(10)
# Agregar una variable transformando
dat <- datos1%>%
mutate(Age_log= log1p(age))
dat %>% head(5)
# Agregar las misma variables transformado en más de una ocasión o variables diferentes
dat1 <- datos1%>%
mutate(Age_sqrt=sqrt(age), Value_log=log(growth_rate))
dat1 %>% head(5)
dat2 <- datos1%>%
mutate(Age_sqrt=sqrt(age), Age_log=log(age))
dat2 %>% head(5)
Acá hay un link con muchos ejemplos: mutate
Ordenar datos de forma descendente o ascendente
arrange
# Ordenar datos en forma descendente
dat1 <- datos1 %>%
arrange(desc(growth_rate))
dat1 %>% head(10)
# Ordenar datos en forma ascendente
dat2 <- datos1 %>%
arrange(growth_rate)
dat2 %>% head(10)
Acá hay un link con muchos ejemplos: arrange
Separar variables que estan delimitadas por algún caracter
determinado separate

head(datos)
tidy <- datos %>%
separate(col=birthdate, into=c('year', 'month', 'day'), sep='-')
tidy %>% head(5)
Acá hay un link con muchos ejemplos: separate
Unir variables que estan delimitadas por algún caracter determinado
unite

tidy2 <- tidy%>%
unite(col=birthdate, c('year', 'month', 'day'), sep='/')
tidy2 %>%
head(5)
Acá hay un link con muchos ejemplos: unite
Separando factores group_by

tidy3 <- datos16%>%
group_by(type_g)
tidy3 %>% head(5)
tidy4 <- datos16%>%
group_by(type_g)%>%
group_by(growth_rate_cut = cut(growth_rate,3))
tidy4%>% head(5)
tidy5 <- datos16%>%
group_by(type_g,edad_g)
tidy6 <- tidy5%>%
summarise(
mean = mean(growth_rate),
sd = sd(growth_rate),
n=n())
tidy6%>% head(5)
Acá hay un link con muchos ejemplos: group_by
Cálculando diferentes tipos de parámetros
summarise
Center: mean(), median()
Spread: sd(), IQR(), mad()
Range: min(), max(),
Position: first(), last(), nth(),
Count: n(), n_distinct()
datos %>%
summarise(mean = mean(growth_rate), n = n())
Acá hay un link con muchos ejemplos: summarise
Separando factores group_by y cálculando estadísticas
descriptivas summarise

# Por nivel
dat <- datos1%>%
group_by(type_g)%>%
summarise(mean_run = mean(growth_rate))
dat %>% head(5)
# Por nivel y separando entre mayores y menores
dat1 <- datos1%>%
group_by(type_g)%>%
summarise(min_R = min(growth_rate),
max_R=max(growth_rate))
dat1 %>% head(5)
# Por nivel y calculando la media de tasa de crecimineto (growth_rate) en relación a los años
dat2 <- datos1%>%
group_by(type_g)%>%
summarise(across(growth_rate:age, mean))
dat2 %>% head(5)
Ejercicios fase III

Después de bajar de una exitosa campaña/muestreo… Encontraste en la
compu que tus datos no estan en formato tidy (como te habian recomentado
Wickman) y ahora debes utilizar las herramientas de tidyverse para poner
todo en orden.
Vamos a utilizar los comandos vistos del
paquete tidyverse para limpiar y analizar los datos de peces de
profundidad desorganizado llamado ‘te_encontre’.
te_encontre <- data.frame(
Nombre = c("Pez1", "Pez2", "Pez3", "Pez4", "Lepidopsetta_mochigarei", "Pez5", "Pez6", "Pez7", "Pez8", "Pez9", "Pez10", "Pez11", "Pez12", "Pez13", "Pez4"),
Color = c("Fluorescente", "Opaco", "Fluorescente", "Opaco", "Fluorescente", "Opaco", "Fluorescente", "Opaco", "Fluorescente", "Opaco", "Fluorescente", "Opaco", "Fluorescente", "Opaco", "Fluorescente"),
PatronBrillo = c("Funky", "Disco", "Funky", "Disco", "Disco", "Funky", "Funky", "Disco", "Funky", "Disco", "Disco", "Funky", "Disco", "Disco", "Funky"),
Longitud = c("10-5", "15-7", "-8-4", "6-3", "12-6", "-9-4", "17-9", "14--6", "9--4", "8--5", "15-8", "10-5", "7-4", "12-7", "18-9")
)Nombre: El nombre del pez.
Color: El color del pez (Fluorescente o No Fluorescente).
PatronBrillo: El patrón de brillo del pez (Funky o Disco).
Longitud: La longitud del pez, expresada en cm.
a. Utilizando dplyr, filtra solo los peces de colores
fluorescentes
b. Utiliza una combinación de comandos ya vistos para
separar la columna ‘Longitud’ en ‘Longitud_total’ y ‘Longitud_cuerpo’,
eliminando cualquier medición sospechosa (como longitudes
negativas).
#> Warning: Expected 2 pieces. Additional pieces discarded in 2 rows [2, 5].c. Vamos a calcular la media de la Longitud_total de los
Funky peces.
d. Buscar la talla maxima de Longitud_total y minima de
Longitud_cuerpo.
Todo parecia facilitar las cosas, hasta que Juan propuso incorporar tidyr
No se preocupén después todo mejora…

Modificando posición de variables gather y
pivot.
datos %>% gather(“key”, “value”, x, y, z) es igual a
datos %>% pivot_longer(c(x, y, z), names_to = “key”, values_to = “val”)

Vamos a ordenar unos datos que encontramos de salidas de barcos a pescar en diferentes días
crudos <- data.frame(dia = c("Lunes", "Martes", "Jueves"),
camarones= c(2, 5, 3), centolla = c(1, 2, 1), langostino = c(3, 4, 3))
print(crudos)
#> dia camarones centolla langostino
#> 1 Lunes 2 1 3
#> 2 Martes 5 2 4
#> 3 Jueves 3 1 3data_long <- crudos%>%
pivot_longer(cols = -dia, names_to = "Especie", values_to = "Salidas")
print(data_long)
#> # A tibble: 9 × 3
#> dia Especie Salidas
#> <chr> <chr> <dbl>
#> 1 Lunes camarones 2
#> 2 Lunes centolla 1
#> 3 Lunes langostino 3
#> 4 Martes camarones 5
#> 5 Martes centolla 2
#> 6 Martes langostino 4
#> 7 Jueves camarones 3
#> 8 Jueves centolla 1
#> 9 Jueves langostino 3data_long2 <-crudos %>%
pivot_longer(cols=c("camarones", "centolla", "langostino"),
names_to='Especie',
values_to='numero')
data_long%>%
pivot_wider(names_from = "Especie", values_from = "Salidas")
Unir dos planillas de datos similares bind_rows()
crudos2 <- data.frame(dia = c("Lunes", "Martes", "Jueves"),
camarones= c(12, 55, 13), centolla = c(21, 12, 21), langostino = c(13, 14, 13))
print(crudos2)
#> dia camarones centolla langostino
#> 1 Lunes 12 21 13
#> 2 Martes 55 12 14
#> 3 Jueves 13 21 13
data_long3 <- crudos2%>%
pivot_longer(cols = -dia, names_to = "Especie", values_to = "Salidas")
print(data_long2)
#> # A tibble: 9 × 3
#> dia Especie numero
#> <chr> <chr> <dbl>
#> 1 Lunes camarones 2
#> 2 Lunes centolla 1
#> 3 Lunes langostino 3
#> 4 Martes camarones 5
#> 5 Martes centolla 2
#> 6 Martes langostino 4
#> 7 Jueves camarones 3
#> 8 Jueves centolla 1
#> 9 Jueves langostino 3
final <- bind_rows(data_long,data_long2)
print(final)
#> # A tibble: 18 × 4
#> dia Especie Salidas numero
#> <chr> <chr> <dbl> <dbl>
#> 1 Lunes camarones 2 NA
#> 2 Lunes centolla 1 NA
#> 3 Lunes langostino 3 NA
#> 4 Martes camarones 5 NA
#> 5 Martes centolla 2 NA
#> 6 Martes langostino 4 NA
#> 7 Jueves camarones 3 NA
#> 8 Jueves centolla 1 NA
#> 9 Jueves langostino 3 NA
#> 10 Lunes camarones NA 2
#> 11 Lunes centolla NA 1
#> 12 Lunes langostino NA 3
#> 13 Martes camarones NA 5
#> 14 Martes centolla NA 2
#> 15 Martes langostino NA 4
#> 16 Jueves camarones NA 3
#> 17 Jueves centolla NA 1
#> 18 Jueves langostino NA 3Acá hay un link con muchos ejemplos: bind
Ejercicios fase III
 León marino ataca a un kayaquista tirándole
un pulpo en la cara…
León marino ataca a un kayaquista tirándole
un pulpo en la cara…
Acá hay un link de la noticia: mamífero+molusco
Volvemos a la data de los mamíferos pero ahora esta data esta como la encontré en internet y me da vagancia llevarla a tidy. Lo hacen ustedes?
busqueda1 <- data.frame(Articulos = c("Diarios", "Revistas", "Tinder"),
Foca_freddy= c(2, 5, 3), Delfín_flipper = c(1, 5, 1), Orca_willy = c(3, 4, 7))
busqueda2 <- data.frame(Articulos = c("Diarios", "Revistas", "Tinder"),
Foca_freddy= c(1, 5, 9), Delfín_flipper = c(8, 1, 2), León_marino_aslan= c(1, 5, 3))a. Por favor, llevar a ambos set de datos a formato tidy
utilizando tidyr y lo que necesiten…
b. Quisiera juntar ambos set de datos en uno.
Agregar varibles nuevas, ya sea por modificación de alguna o
incorporando una nueva _join()
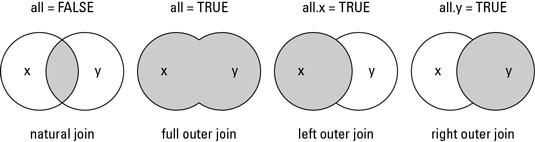
La función joins añade columnas de y a x y se unen en base a su denominación:
inner_join() : incluye todos las filas en x y en y.
left_join(): incluye todas las filas de en x.
right_join() : incluye todos las filas en y.
full_join(): incluye todas las filas en x o en y.
semi_join(): …
anti_join(): …
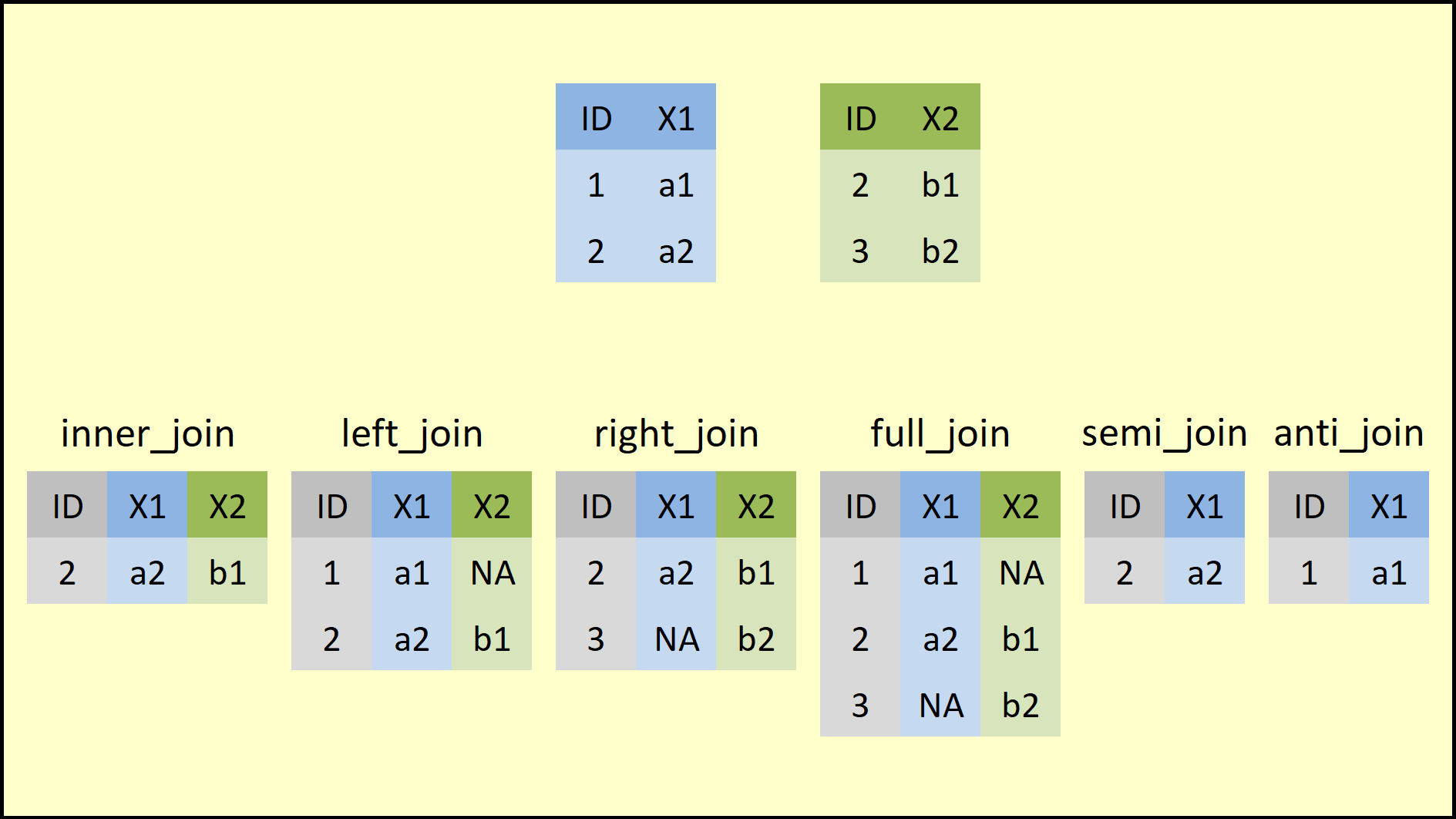
# Invento datos para visulizar las funciones con fácilidad
data1 <- data.frame(ID = 1:2,
X1 = c("a1", "a2"))
data2 <- data.frame(ID = 2:3,
X2 = c("b1", "b2"))
print(data1)
#> ID X1
#> 1 1 a1
#> 2 2 a2
print(data2)
#> ID X2
#> 1 2 b1
#> 2 3 b2
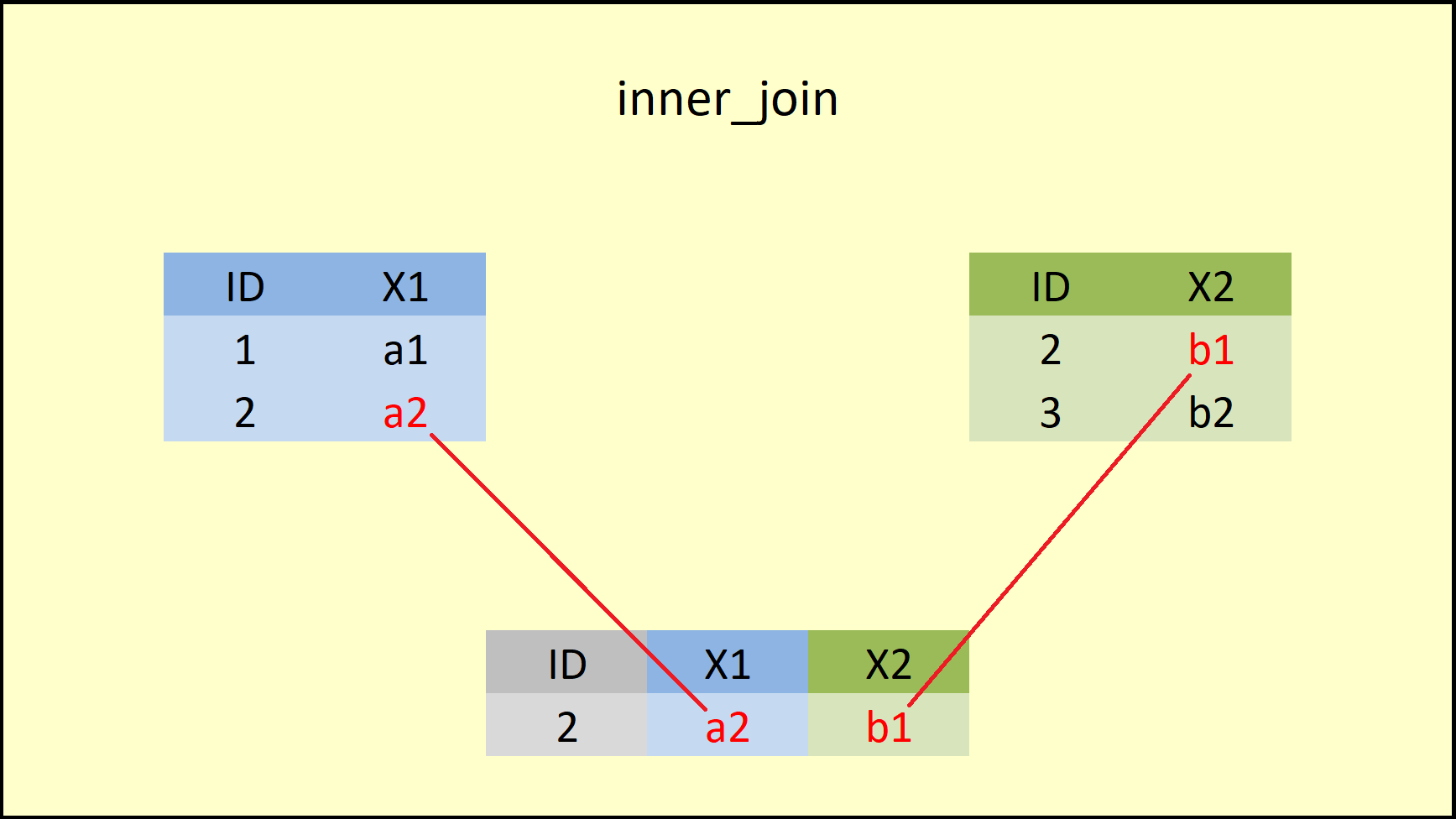

da1 <- inner_join(data1, data2, by = "ID")
print(da1)
#> ID X1 X2
#> 1 2 a2 b1
# Invento datos para visulizar las funciones con fácilidad
data1 <- data.frame(ID = 1:2,
X1 = c("a1", "a2"),
stringsAsFactors = FALSE)
data2 <- data.frame(ID = 2:3,
X2 = c("b1", "b2"),
stringsAsFactors = FALSE)
print(data1)
#> ID X1
#> 1 1 a1
#> 2 2 a2
print(data2)
#> ID X2
#> 1 2 b1
#> 2 3 b2
da1 <- inner_join(data1, data2, by = "ID")
print(da1)
#> ID X1 X2
#> 1 2 a2 b1
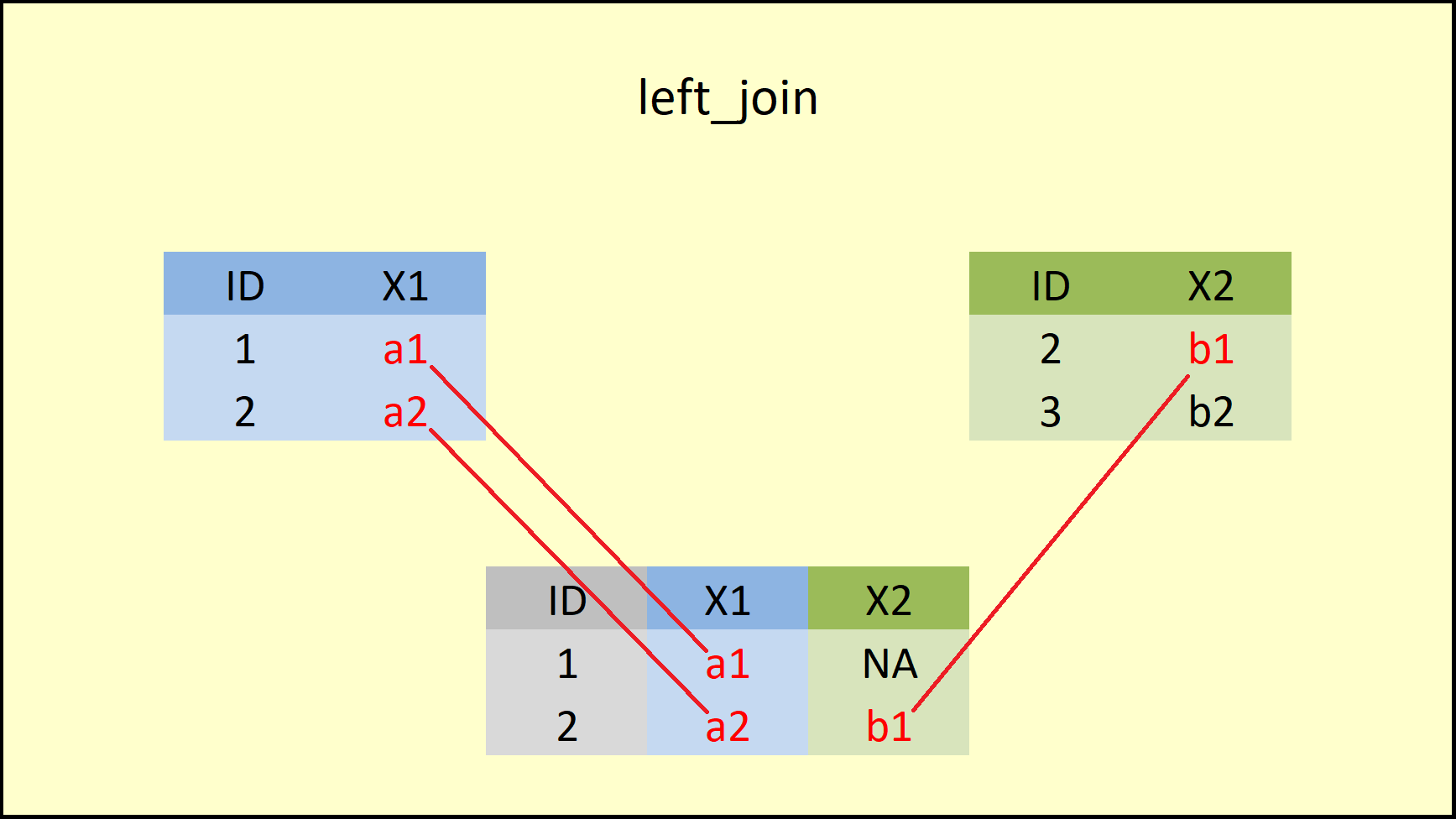

da2 <- left_join(data1, data2, by = "ID")
print(da2)
#> ID X1 X2
#> 1 1 a1 <NA>
#> 2 2 a2 b1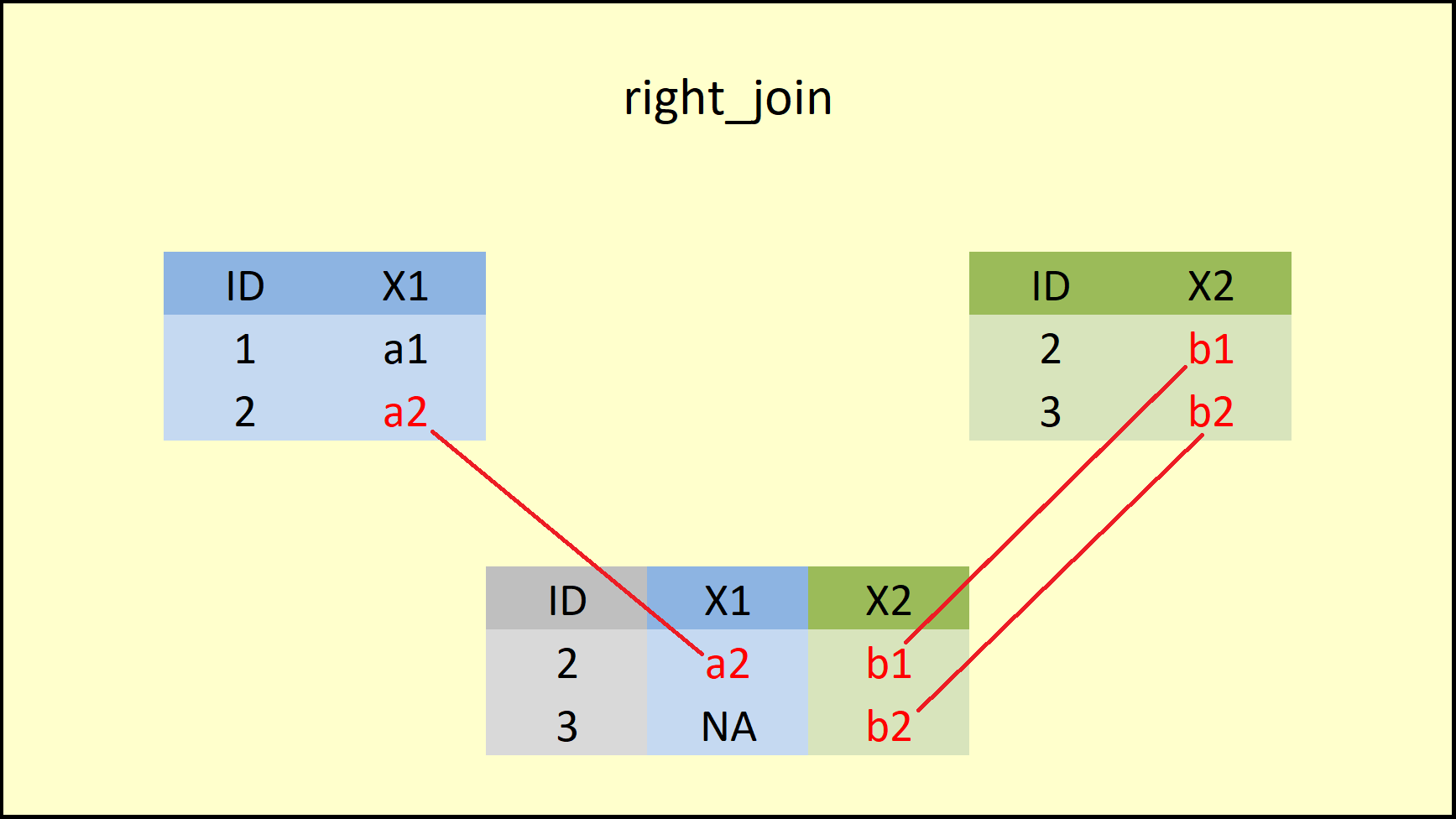

da3 <- right_join(data1, data2, by = "ID")
print(da3)
#> ID X1 X2
#> 1 2 a2 b1
#> 2 3 <NA> b2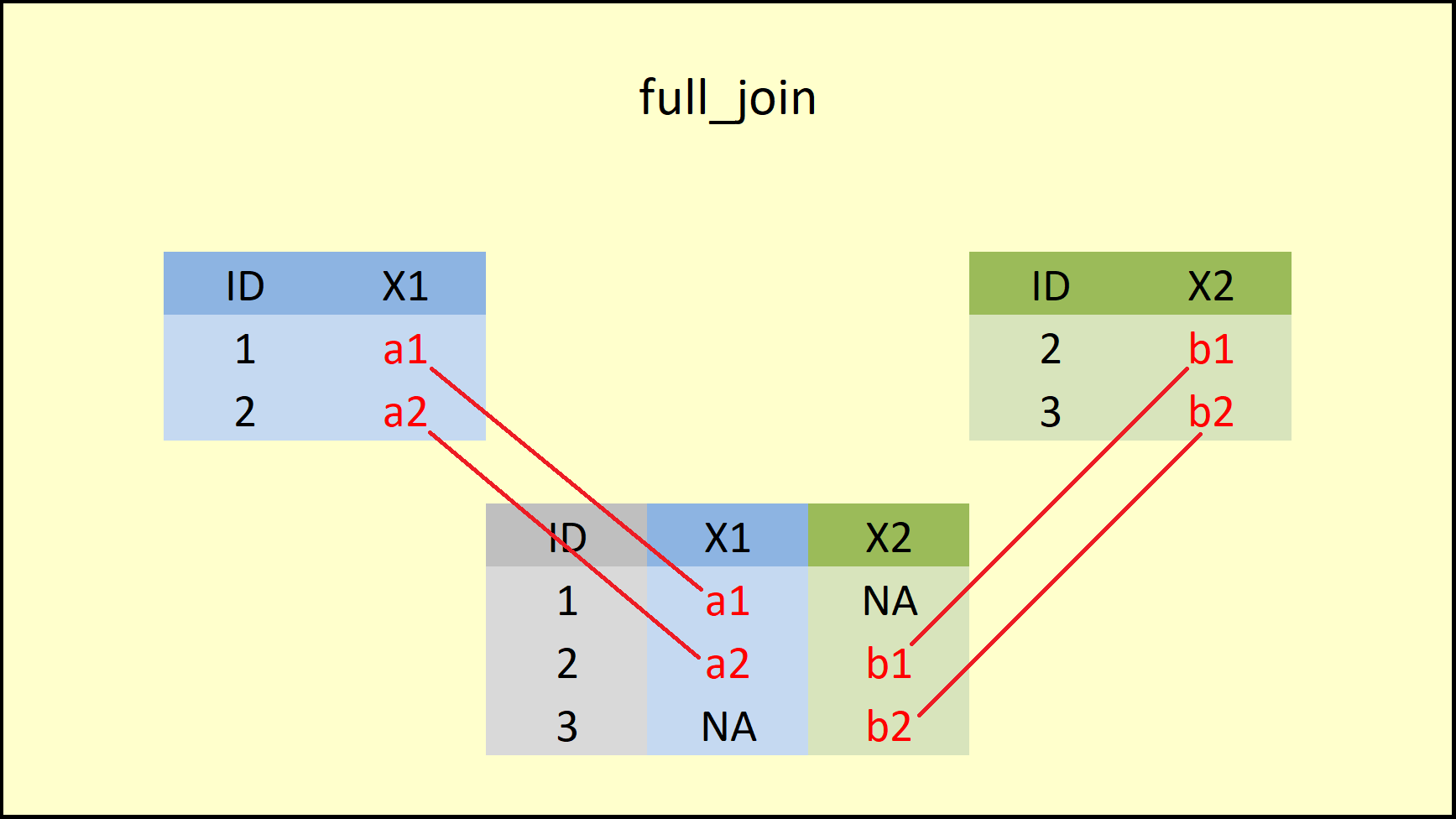

da4 <- full_join(data1, data2, by = "ID")
print(da4)
#> ID X1 X2
#> 1 1 a1 <NA>
#> 2 2 a2 b1
#> 3 3 <NA> b2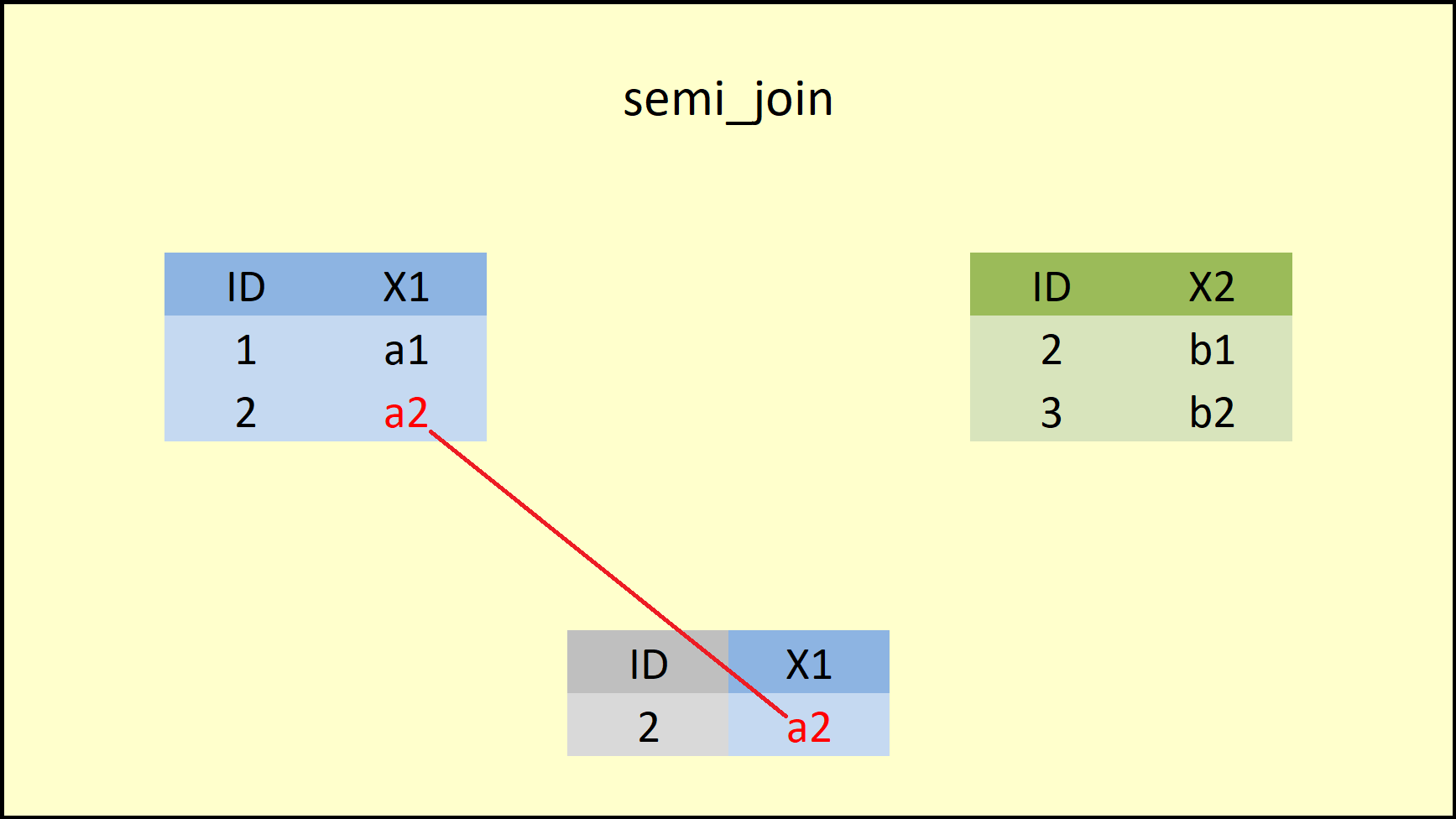

da5 <- semi_join(data1, data2, by = "ID")
print(da5)
#> ID X1
#> 1 2 a2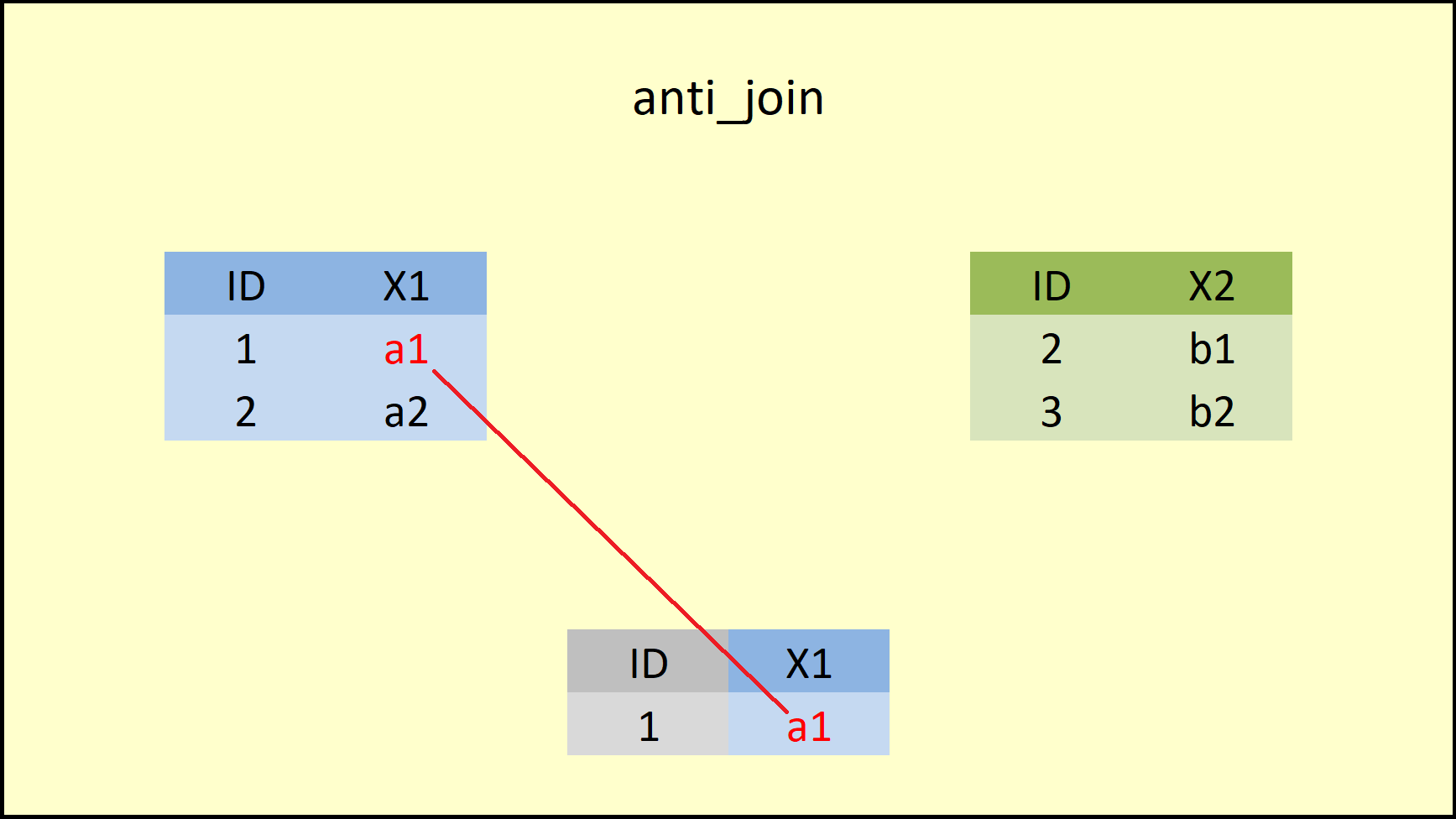

da6 <- anti_join(data1, data2, by = "ID")
print(da6)
#> ID X1
#> 1 1 a1
da6 <- anti_join(data1, data2, by = "ID")
print(da6)
#> ID X1
#> 1 1 a1
### Ahora sumamos más datos
# Otro set de datos más para hacer algo multiple
data3 <- data.frame(ID = c(2, 4),
X2 = c("c1", "c2"),
X3 = c("d1", "d2"),
stringsAsFactors = FALSE)
da7 <-full_join(data1, data2, by = "ID") %>% # Porque X2 coincide en X1 y X3
full_join(., data3, by = "ID")
print(da7)
#> ID X1 X2.x X2.y X3
#> 1 1 a1 <NA> <NA> <NA>
#> 2 2 a2 b1 c1 d1
#> 3 3 <NA> b2 <NA> <NA>
#> 4 4 <NA> <NA> c2 d2
da8 <-full_join(data2, data3, by = c("ID", "X2")) # Acá queda afuera data1
print(da8)
#> ID X2 X3
#> 1 2 b1 <NA>
#> 2 3 b2 <NA>
#> 3 2 c1 d1
#> 4 4 c2 d2
da8 <-inner_join(data1, data2, by = "ID") %>% # Así podemos borrar ID
select(- ID)
print(da8)
#> X1 X2
#> 1 a2 b1
Acá hay un link con muchos ejemplos: mutate-joins
Ejercicios fase IV

a. Vamos a juntar los datos utilizando fish_code como
variable común y juntando los datos en los cuales solo hay
coincidencia
b. Vamos a juntar los datos utilizando fish_code como
variable común y juntando todos los datos
c . Vamos a juntar los datos utilizando fish_code como
variable común y juntando los que no coincidan
Ejercicios integrativo (opcional)
